Building an End-to-End Contract Discovery System
Background
Red Hat’s Sales and Deal Management team recently faced a significant challenge: migrating hundreds of thousands of documents from our legacy Salesforce CRM to the new Sales Cloud system. This migration is necessary to maintain efficient access to historical contract data, which is crucial for generating new contracts with existing clients and partners. The sheer volume of documents made manual migration impractical, risking millions in potential revenue and increased operational costs due to inefficient contract analysis.
To address this, we developed RHContract.AI, a contract discovery tool that utilizes large language models (LLMs) to extract relevant attributes from legacy contracts and facilitate migration to the new system.
This post will outline the development of RHContract.AI, including an overview of the system, technical details, and insights into the development process. I’ll also share my personal journey in building this product, including the challenges we overcame and the valuable lessons learned along the way.
Product Overview
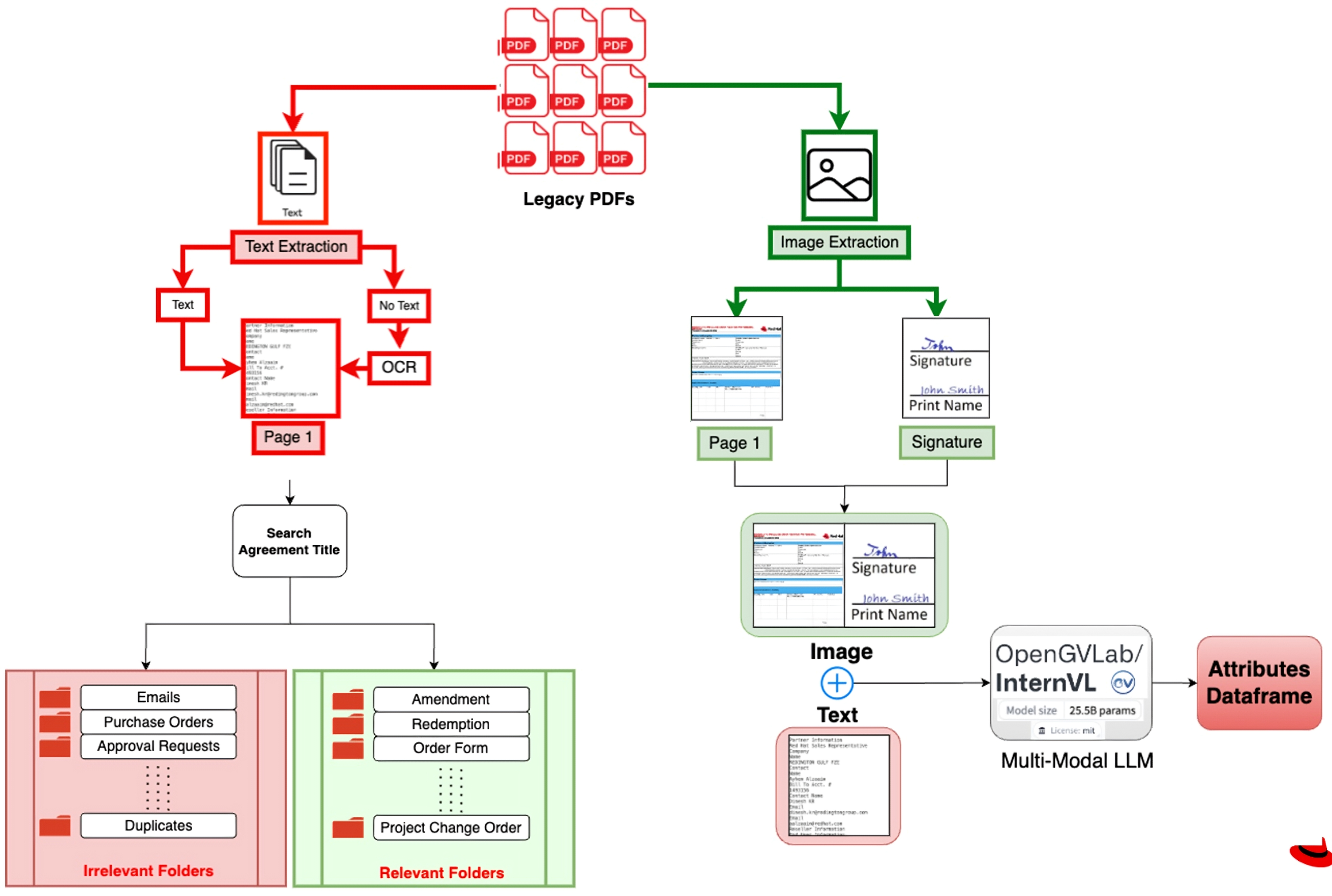
On a high level, our system processes document data through three main stages:
- Input: ingests a data dump of documents alongside predefined document type and attribute definitions.
- Processing: analyzes and categorizes the documents based on the predefined types.
- Output: generates two key deliverables:
- A structured directory of organized document types.
- A DataFrame that maps file names to their extracted attributes.
Key Features
We focused on delivering these essential capabilities for our Minimum Viable Product (MVP):
- Contract Filtering: Accurately identify and segregate contract documents from non-contract files.
- Attribute Extraction: Extract key information as defined by the Red Hat Sales team.
- Signature Detection: Determine whether contracts are signed or unsigned.
- Multilingual Support: Process contracts in languages other than English.
Development Approach
Our development process was structured around implementing each key feature as a distinct stage. This approach offered enhanced visibility into the system’s performance at each step of the process, allowing us to iterate quickly and improve individual components as needed. By compartmentalizing features, we could easily identify bottlenecks, optimize specific stages, and ensure the overall system was functioning efficiently before moving on to the next phase of development.
Performance Metrics
To measure the effectiveness and impact of our product, we established the following Key Performance Indicators (KPIs):
- Filtering Accuracy: Precision in identifying contract types and filtering out irrelevant PDFs.
- Extraction Accuracy: Correctness of attribute extraction across various contract types.
- Signature Detection Accuracy: Reliability in distinguishing between signed and unsigned documents.
- Time Savings: Quantified reduction in processing time for sales and partner associates (measured per deal/week/day/month).
Contract Classification
We implemented contract classification to filter the initial document dump into categories, allowing us to analyze the distribution of documents. This iterative process involved:
- Identifying distinguishing keywords for each relevant document type.
- Running keyword searches against the documents.
- Categorizing documents into folders based on their type.
- Refining the process by identifying additional keywords from unclassified documents.
First, we implemented a deduplication step that compares file content hashes, marking documents as duplicates when hashes match.
Most documents were in PDF format, making text extraction relatively inexpensive using libraries like PyMuPDF. Documents without text were categorized as images for further processing. We continued this process until reaching a steady state of relevant and irrelevant documents, ensuring confidence in our filtering module.
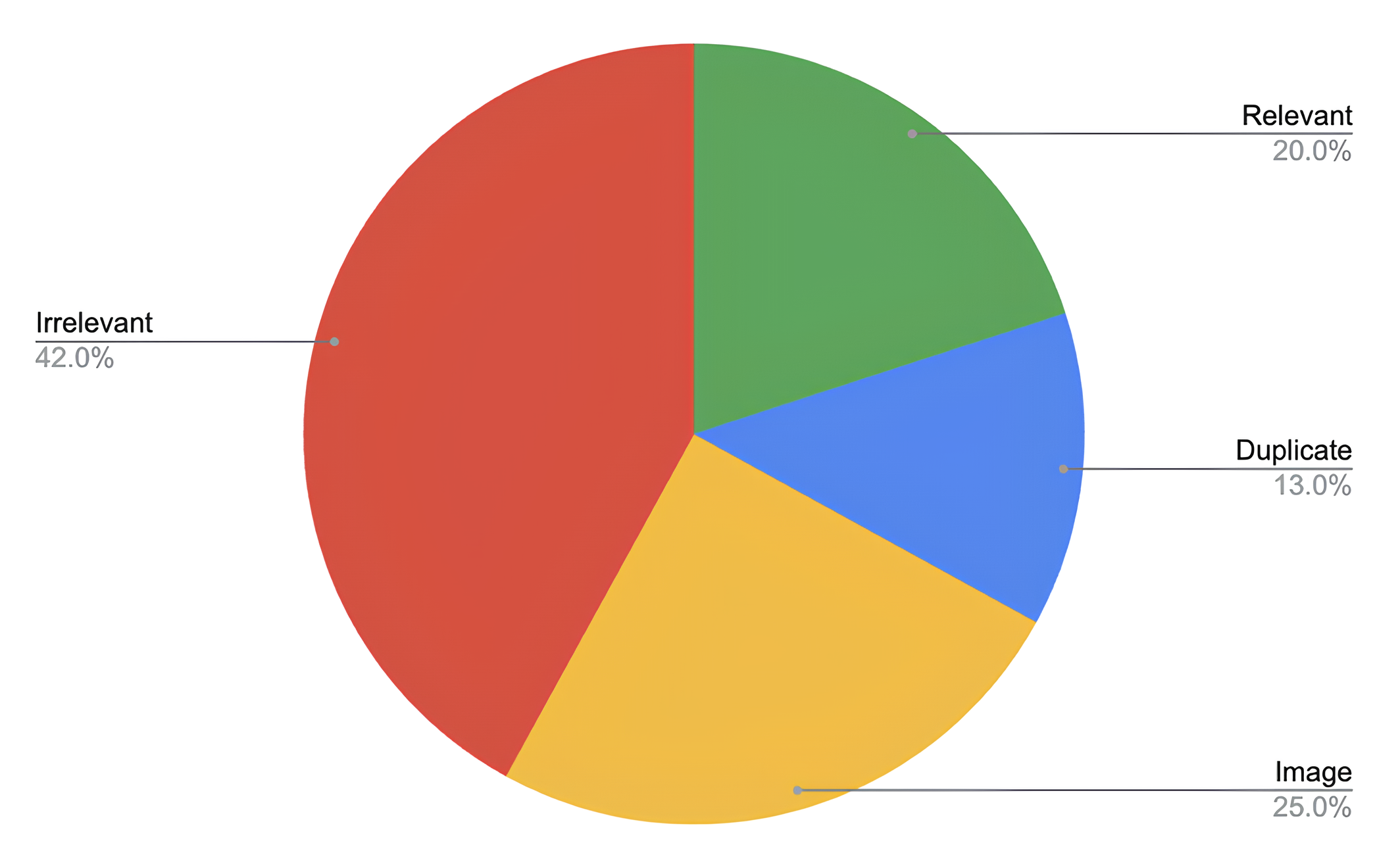
After filtering the subset of documents, nearly 50% were deemed irrelevant, and over 10% were identified as duplicates. This resulted in removing more than half of the documents from the time-consuming attribute extraction process.
Furthermore, after applying Optical Character Recognition (OCR) to image documents and reclassifying them, 50% of these documents were found to be relevant. This increased the overall proportion of relevant documents to 30% of the total unprocessed set.
Attribute Extraction
Following document classification, we tackled the challenge of extracting relevant attributes from each document type. Our initial experiments with traditional LLMs did not yield promising results. The primary issue was the distortion of document structure during PDF text extraction, which led to mixed-up words and sentences, causing LLMs to misinterpret the content. To overcome this, we shifted our focus to multimodal LLMs, specifically InternVL2 by OpenGVLab, an Apache 2.0 licensed model with 26 billion parameters. This approach was significantly more effective. By feeding both the document image and text into the model, we observed a huge increase in attribute extraction accuracy, often surpassing 90% — an improvement of several orders of magnitude over our initial attempts.
The InternVL2 model, particularly its text component InternLM2Chat, showed strong instruction comprehension compared to previous LLMs. Unlike our previous attempts, where we struggled to get clean JSON outputs, InternLM2Chat consistently delivered well-formed JSON that we could easily parse with Pydantic classes. Although inference latency increased slightly, the trade-off was worth it given the accuracy boost. Additionally, working with JSON made our lives easier down the line. We could quickly merge the output into Pandas DataFrames and export to CSV or other compatible formats.
Signature Detection
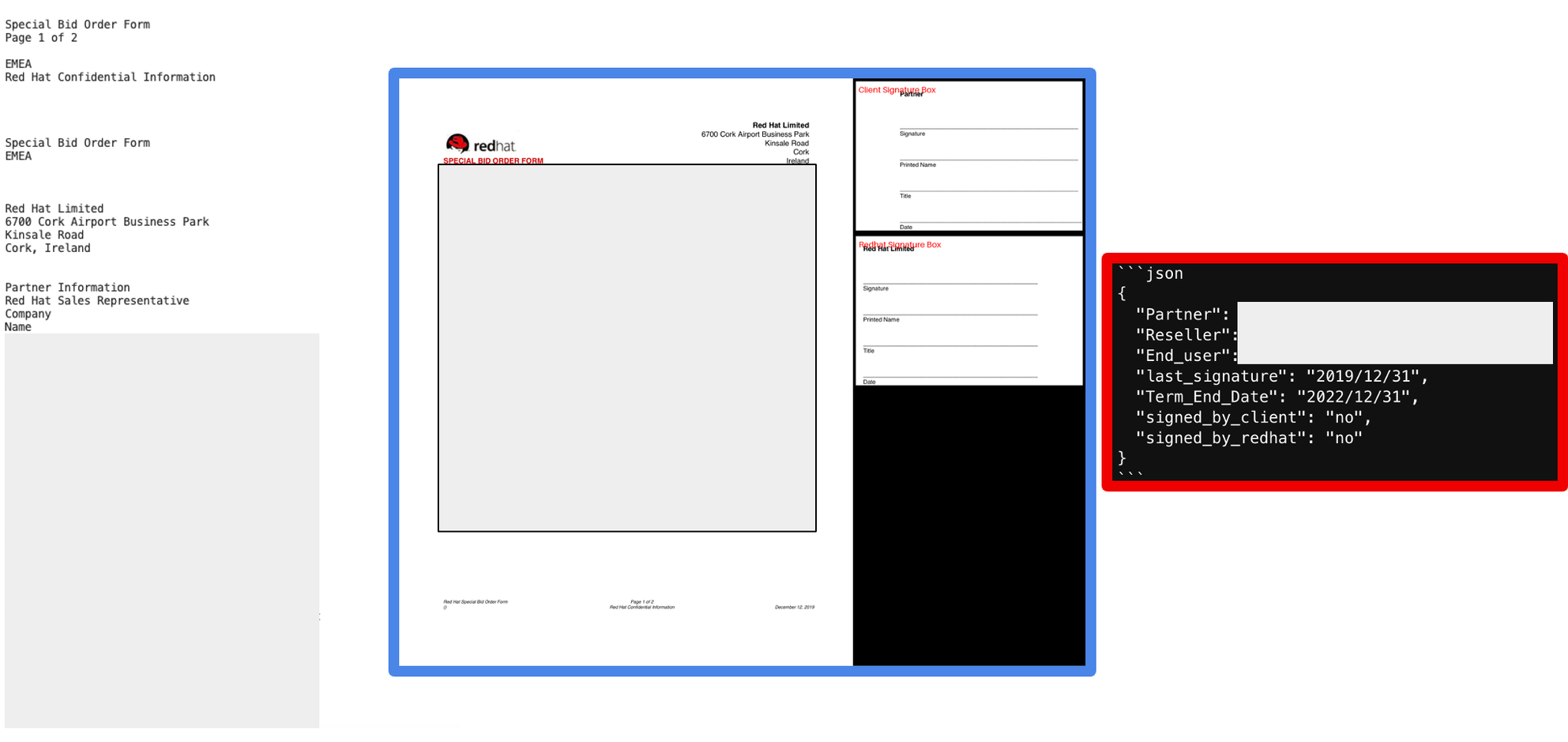
Signature detection was another hurdle to overcome in our contract analysis process. Our task was to determine whether Red Hat or the client, or both parties, had signed the contract. Initial attempts yielded disappointing results, with accuracy hovering around 50%. We began by feeding the model the first page of the contract, which contained the main attributes, along with the signature page as an image. We identified the signature page through keyword searches in the document text. However, this approach provided too much information for the model to process effectively, as it ended up hallucinating results and misinterpreting the document (similar to that in attribute extraction).
We came up with the idea of segmenting the signature page into two distinct parts: one for the client’s signature and another for Red Hat’s. We extended our keyword search algorithm to identify relevant coordinates and extract these specific sections as images. These signature snippets were then appended to the original first page, as illustrated in the image above (with redactions for privacy reasons).
This refined approach yielded two significant benefits. Firstly, we observed a substantial improvement in accuracy, with rates increasing to between 85% and 95%. Secondly, the inference time improved due to the reduced image size, allowing us to process larger batches using the same compute.
After making considerable headway, we focused on iterative improvements. We continuously refined our prompts, striving for a balance between conciseness and specificity. Our goal has been to optimize the trade-off between processing speed and accuracy, which has been crucial in enhancing the overall performance of our signature detection system.
Lessons Learned
This project marked my first deep dive into working with LLMs. Before this, my experience was limited to tinkering with OpenAI’s APIs on a small chatbot project when the LLM development ecosystem was still in its early stages.
The LLM landscape has undergone rapid transformation in recent years. Today, developers have access to dozens of tools for building fully-fledged LLM products, with LangChain serving as a prime example. Despite these upgrades in tooling, some fundamental concepts have remained crucial to success in LLM development.
Importance of Quality Input Data
One of the most significant lessons we learned was the critical role of high-quality input data. We quickly realized that the model’s performance suffered when overloaded with text and images from documents. To address this, we dedicated substantial effort to refining our input. This involved removing unnecessary text, formatting the remaining content, and selectively serving only the most relevant pages to the model, such as the first page and signature page where most attributes tend to reside. These efforts resulted in reduced hallucinations, and greatly improved inference time and accuracy.
Leveraging External Resources
Our success would not have been possible without the wealth of online resources sharing effective LLM development techniques. Equally important was maintaining open communication with our stakeholders (internal sales team). Through these regular interactions, we gained valuable insights into their pain points and clearer understanding of business definitions. This knowledge allowed us to craft focused prompts that provided richer context to the LLM, significantly improving its performance.
Adopting a Startup Mindset
Building this project from scratch required us to operate with a startup mentality. This approach meant moving fast and being willing to discard previous work when necessary. While I enjoyed the thrill of rapid progress and quick accomplishments, I also had to come to terms with the fact that our past ideas might not always be useful in the next sprint. We had to throw out about half our work in the previous sprint regularly. For instance, I invested significant effort early in the project in developing an experiment to compare performance between various open-source models. When we pivoted to multimodal LLMs and settled on a single model, my work became obsolete. Rather than viewing this as a setback, I recognized it as a necessary step in our progress.
Forward-Thinking Approach
Perhaps the most crucial lesson was the importance of being forward-thinking and constantly moving towards what would work best for the product. Our transition from local computing resources to a more powerful cloud-based computing architecture is a great example. Initially, we were experimenting locally on Ollama using 4-bit quantized models. However, we soon hit a performance ceiling in terms of speed and accuracy. Recognizing that scaling our product would require more robust computing power, we proposed leveraging high-performance GPUs to our mentors, and were fortunate to be granted access to a 2x A100 GPU cluster in the cloud (shoutout ROSA). This upgrade was key in our continued iteration and improvement of the product.