Building an On-Device Automobile Assistant
Disclaimer: I wrote my first blog post two years ago, proud to have done it without any help from LLMs. This time, I have fully embraced them to speed up and sharpen my writing. That said, most LLM-generated text tends to share the same stylistic tone, so copy-pasting isn’t ideal. For technical posts like this, the challenge is balancing clarity with brevity. The core ideas still have to come from the writer, but LLMs provide the vocabulary and structure that make those ideas easier to read. I don’t expect that dynamic to change. Creative work, whether writing or coding, remains an iterative process, where each step refines the alignment between prose and concept.
Introduction: The Era of AI-Defined Vehicles
The automotive industry is entering a new era: the AI-defined vehicle. Arm envisions embedding AI at the core of automotive compute, enabling vehicles to sense, reason, and adapt in real time to driver needs and the environment. With platforms like Zena CSS, powerful and secure AI processing can now happen directly inside the vehicle. Local intelligence not only enhances privacy and responsiveness but also unlocks new levels of safety, convenience, and personalization.
This project is a step toward this vision: building an on-device, agentic multimodal assistant that demonstrates how modular, collaborative AI can enhance in-vehicle experiences, all running efficiently on local hardware. In this paradigm, AI agents are integral, proactive partners for drivers, collaborating to assist with everything from diagnostics to environmental control.
Glossary
Agent
A modular software component responsible for a specific capability. Each agent processes its own inputs and outputs, and communicates with others through defined interfaces.
Supervisor
The coordinating agent that interprets user intent and routes tasks to the appropriate agent or tool. It serves as the dispatcher that ensures each request is handled by the right component.
Retrieval-Augmented Generation (RAG)
A technique that improves accuracy by retrieving relevant passages from a local knowledge base (vector store) and providing them as context to the language model. This allows the assistant to answer vehicle-specific questions without internet access.
Vector Store
A database that stores embeddings (numeric representations of text or images) so semantically similar items can be retrieved quickly.
Quantization
A compression technique that represents model weights with fewer bits (e.g., 32‑bit to 4-bit) to reduce memory usage and speed up inference, allowing large models to run on resource-constrained on-device hardware.
On-Device/Edge Inference
Running AI models directly on the vehicle’s compute, enhancing privacy and reliability.
System Architecture: Modular Intelligence on the Edge
The assistant’s architecture is designed around modular agents that each handle a specific capability: guardrail, vehicle control, retrieval, and vision. The Supervisor Agent coordinates these components, dispatching tasks based on user intent and system context.
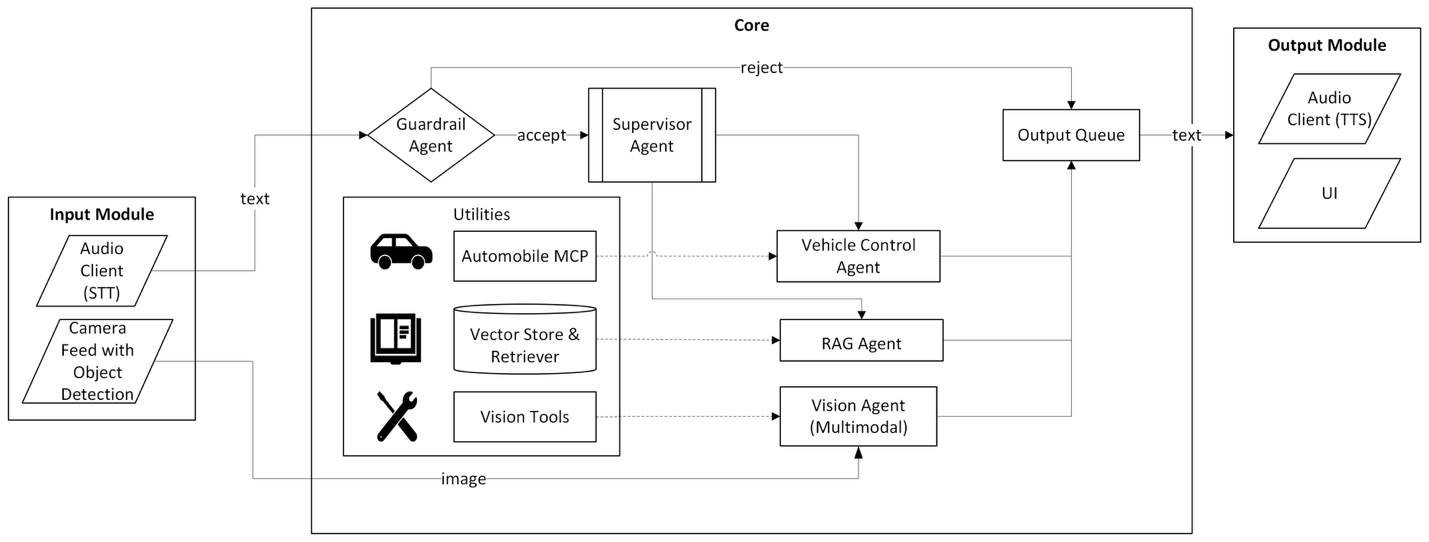
Components
Input Module
Converts spoken queries to text via whisper.cpp and forwards them to the Guardrail Agent. It also pulls image data from the camera at a configurable frequency for the Vision Agent.
Guardrail Agent
Validates user input and rejects unsafe or malicious instructions, such as access system prompts or override safety-critical controls.
Supervisor Agent
Receives validated input and determines which agent or tool to invoke. This interface scales by keeping a registry of available tools and agents, each described in a consistent format, so new functionality can be plugged in easily without altering the Supervisor’s core logic.
Vision Agent
Uses a Vision-Language Model (VLM) to analyze camera feeds (e.g., whether the driver is adhering to traffic rules).
Output Queue
Serves as an intermediary between the core agent system and the output module. This component ensures responses are delivered in the correct order to the Output Module (whether for speech synthesis or user interface), thereby maintaining consistency and reliability in driver-facing outputs.
Utilities
Agents interact with a set of local tools exposed through the Model Context Protocol (MCP) server or as direct function calls. These tools represent the assistant’s interface to the vehicle and its supporting systems. In the current prototype, they are stubbed with mock data, but the design anticipates integration with real automotive subsystems.
- Driving and Safety
- Contact emergency services in the event of a crash or detected hazard.
- Configure vehicle environment settings such as climate control, sunroof, and cabin lighting.
- Send notifications and alerts to the driver.
- Personal Assistance
- Retrieve vehicle information from a local vector database (via RAG).
- Control infotainment features, such as Bluetooth connections and media playback.
By exposing these capabilities as modular tools, the system maintains a clean separation between reasoning (agents) and actuation (tools), ensuring extensibility and easier integration with new automotive features in the future.
Example Input-Output Sequence
Suppose the driver says, “Pair my phone to the car’s Bluetooth.”
Input Module
Transcribes the driver’s speech into text.
Core
Guardrail Agent
Validates the request to ensure it is safe and within scope.
Supervisor Agent
Interprets the intent as an environment control task and routes it to the Vehicle Control Agent.
Vehicle Control Agent
Calls the Automobile MCP tool to handle Bluetooth pairing with the driver’s device and outputs the result.
Output Queue
Buffers the result, ensuring they are delivered in order and not interrupted by concurrent tasks.
Output Module
Sends responses to the TTS client and UI.
The assistant then confirms: “Your device has been paired successfully.”
The following logs capture how the system executes the request in real time. Each entry corresponds to a step in the pipeline. Excluding the time required to connect the Bluetooth device, the agent workflow completes in under five seconds.

Model and Hardware Configuration
The system runs with two models in memory:
- A large VLM (InternVL3-Instruct 14B) for image-text reasoning in the Vision Agent.
- A smaller LLM (Jan-nano 4B), for all other text tasks, including retrieval and tool orchestration.
Both models are quantized to 4-bit and served via llama.cpp. We selected Unsloth’s Dynamic 2.0 GGUF format, which offered the best trade-off between model size and runtime performance among leading quantization methods. This allowed both models to fit within 14 GB of VRAM.
We developed the assistant prototype on an Amazon EC2 g5g.4xlarge instance, equipped with 16 Arm‑based Graviton2 vCPUs, 32 GB of RAM, and a T4G Tensor Core GPU with 16 GB of VRAM. The entire compute and memory footprint is largely dedicated to running ML workloads, which aligns with real-world vehicle constraints: a car in 2025 contains 16 GB of DRAM on average, with this amount projected to triple by 2026. This parity ensures our development environment mirrors the resource budget available for production-capable AI agents. Additionally, the use of Graviton2 supports Arm’s SOAFEE framework, enabling the development and testing of containerized automotive workloads in the cloud before deploying to in-vehicle systems.
Design Implications
Overall, this architecture supports multimodal interaction, operates reliably without reliance on external connectivity, and can be extended by adding new agents, tools, or capabilities with minimal changes to existing components.
Progressive Capabilities
The assistant has been developed in stages, with each stage introducing new perception and action capabilities. This incremental approach illustrates how the system advances from basic information retrieval to context-aware autonomy.
Level 1: Inspect Vehicle Status using Voice Commands
At the base level, the assistant can retrieve real-time vehicle state from onboard sensors in response to spoken queries (e.g., “What is the current cabin temperature?”). This provides immediate, hands-free access to vehicle information.
Level 2: Modify Vehicle Status using Voice Commands
Building on retrieval, the assistant can execute driver commands to adjust vehicle settings (e.g., “Set the temperature to 70 degrees”). This shifts the role of the assistant from an information source to an active participant in the vehicle operation.
Level 3: Visual Interpretation and Driver Alerts
With vision integrated, the assistant begins to understand the driving environment through real-time visual input. For instance, it can detect when the vehicle is in a High Occupancy Vehicle (HOV) lane and issue a warning if the occupancy requirement is not met. Here, the assistant reasons over complex, dynamic, real-world situations, interpreting context, not just following instructions.



Level 4: Visual-Informed Autonomous Action
The assistant combines deep visual understanding with autonomous decision-making to deliver critical safety interventions. For instance, in the event of a detected crash, the assistant can autonomously contact emergency services, ensuring help is dispatched even if the driver is unable to respond.
This capability marks a shift from passive monitoring to active, situational response: the assistant not only perceives and interprets its environment but also acts decisively to ensure driver safety.



Altogether, these progressive levels demonstrate a clear trajectory from simple sensor queries to autonomous, context-aware behavior. Each step brings us closer to in-vehicle assistants that can truly perceive, understand, and act within the vehicle environment, paving the way toward fully AI-defined mobility.
Key Learnings
Designing for Scalability
We compared two common approaches to designing agentic systems.
- A monolithic architecture, where a single large agent manages all tasks
- A modular architecture, where a supervisor agent acts as a router and facade for specialized sub-agents.
Internal evaluations indicate that the modular approach scales more effectively and delivers more consistent results. It allows individual components to be updated or extended without disrupting the overall system, much like replacing a car part without rebuilding the entire engine. Our observations are consistent with findings from LangChain, which demonstrate that supervisor-based multi-agent architectures maintain performance as the number of tools grows, while single-agent systems degrade rapidly when overloaded with context or capabilities.
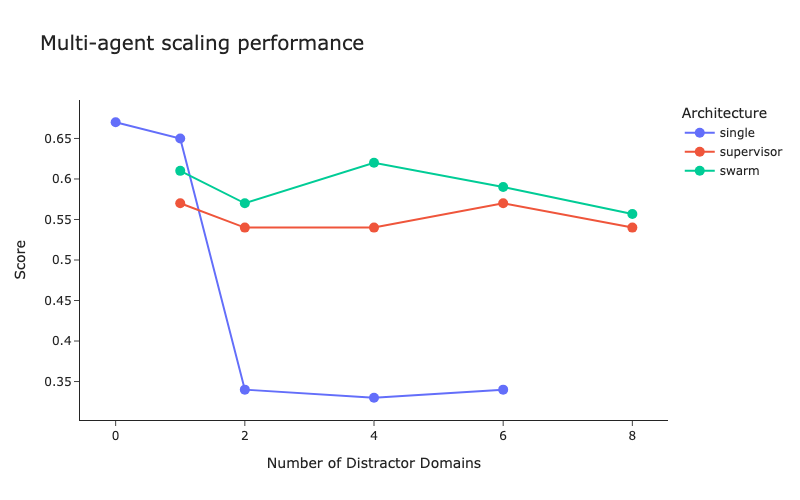
Enabling Real-Time Inference on Constrained Hardware
Running AI models on edge hardware is challenging due to tight compute and memory budgets. To address these constraints, we routed requests between the VLM and the compact LLM and applied 4-bit quantization to both. The larger VLM delivers strong multimodal reasoning but incurs higher latency, so non-vision tasks are routed to the LLM to maintain responsiveness. This division of labor achieves a balance between functionality and responsiveness, enabling real-time multimodal inference for automotive workloads on resource-constrained devices.
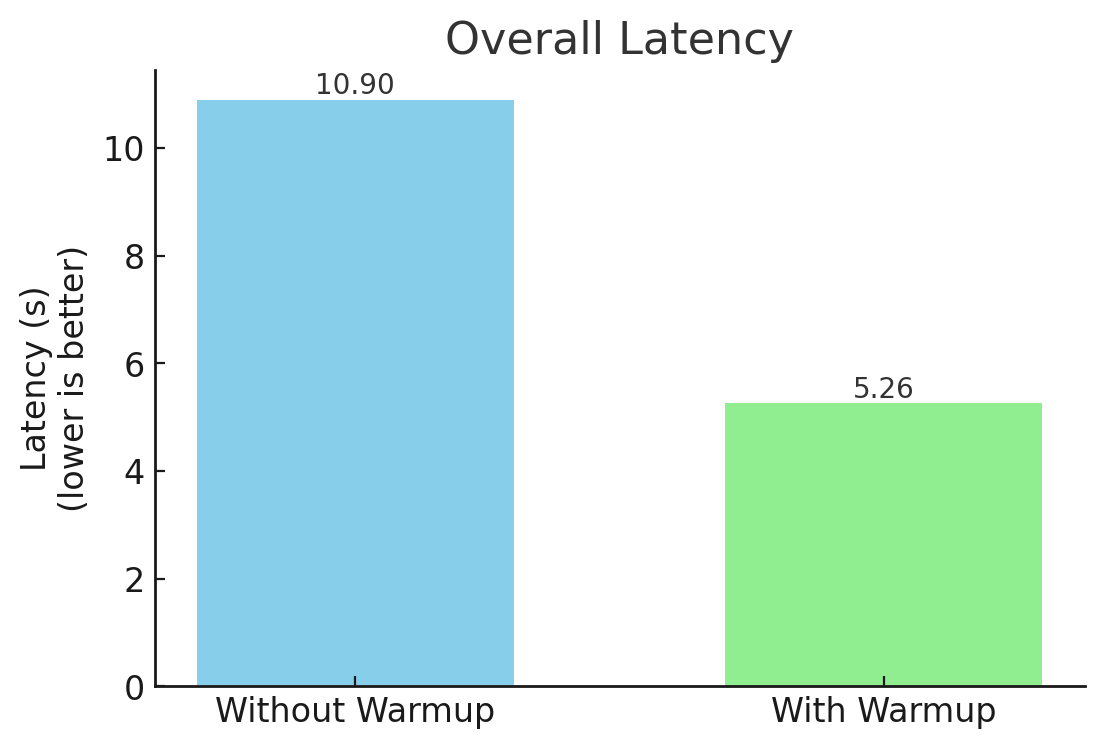
We further reduced latency by precomputing the KV cache for the system prompt because it is reused as the prefix for all conversations. In ablation tests, this warm-up procedure delivered an average 2x speedup in end-to-end latency.
Enhancing Accuracy with On-Device RAG
Incorporating RAG transformed the assistant’s responsiveness and reliability. By embedding a knowledge base like the car manual, the assistant can answer context-aware, technical questions swiftly and privately without an internet connection. This dramatically improves real-time usefulness and driver trust.
Multimodal Understanding Unlocks New Possibilities
Integrating a vision component was pivotal. It transformed the assistant from just a listener to a context-aware observer that could understand visual cues inside and outside the vehicle (such as passenger safety or lane conditions), enabling more intuitive and proactive behavior.
Observability Enables Faster Iteration
We equipped the system with MLflow tracing to gain visibility into each agent’s execution time, tool usage, and handoff flow. This observability accelerates debugging, performance tuning, and design improvements as the system matures.
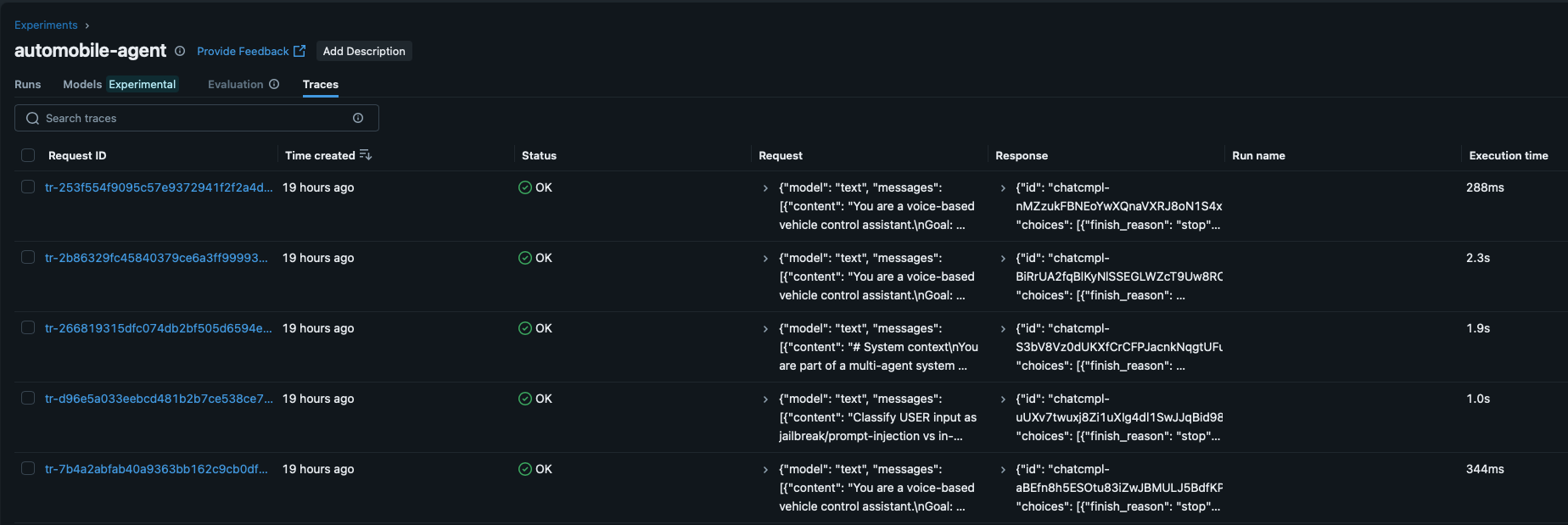
Constraining Agent Capabilities
Our architecture enforces strict constraints on agent behavior to ensure safety and reliability. Each agent accesses only the minimal set of tools it requires, keeping its scope contained through the principle of least privilege. The Guardrail Agent provides containment by screening all inputs using rule-based checks, blocking unsafe or out-of-scope commands before they reach sensitive tools. We validate robustness against malicious or adversarial inputs through testing frameworks like DeepEval, reducing the risk that sophisticated input manipulation could trigger unintended agent behavior.
Call to Action
To transition this agentic, on-device automobile assistant from prototype to real-world deployment, we must carefully balance four interdependent priorities: model intelligence, latency, memory usage, and safety.
Advancing model intelligence on edge hardware requires progress in post-training techniques such as pruning, quantization, and knowledge distillation, which enable compact models to maintain strong performance despite limited parameter capacity. Further reductions in latency depend on improvements in hardware architecture to address memory-bound inference. For example, placing compute closer to memory can minimize data movement bottlenecks. Optimizing memory usage also requires hardware-aware strategies, including quantization-aware training, efficient attention implementations, and robust, lightweight model architectures, ensuring models can operate within strict VRAM budgets while remaining functional.
Most critically, safety must be embedded at every layer. Since Arm’s IP supports ISO/SAE 21434 compliance, this system is well-positioned to align with automotive cybersecurity standards. However, deploying such a system at scale requires alignment with industry-wide validation practices and thorough adversarial testing to meet both technical and regulatory requirements. Addressing these interwoven challenges through continued optimization, security risk engineering, and cross-industry collaboration will be vital for bringing safe, capable, and real-time AI assistants to the vehicles of the future.
Looking Ahead: The Future of In-Car Intelligence
This prototype is just the beginning. The next frontiers for on-device assistants are:
Proactive, Context-Aware Reasoning
By leveraging world models, AI systems that learn and simulate real-world dynamics, future assistants can not only respond to human inputs and predefined triggers, but also anticipate scenarios, plan actions, and adapt to long-term consequences. Training these models in rich virtual environments will allow them to handle complex driving conditions safely and reliably, before ever hitting the road.
Personalized, Continual Learning
Future assistants will continuously adapt to each driver. Efficient fine-tuning techniques like QLoRA could allow models to adapt to the users’ unique preferences, driving style, and specific vehicle vocabulary over time, making interactions feel more natural and tailored to each individual.
Closing Thoughts
We are only scratching the surface of what’s possible when powerful, privacy-first AI resides directly in your car. The agentic assistant developed here demonstrates that intelligent, collaborative, and extensible in-vehicle AI is within reach, and that every incremental advance in software and hardware brings us closer to cars that are not just a mode of transport, but truly intelligent and intuitive partners on every journey.