Intro to LSM Tree
Introduction
Log-Structured Merge-Tree (LSM-Tree) is an append-only, key-value data structure that provides high write throughput. Write throughput is the amount of data that can be written to a storage system over a period of time. LSM Tree is used by various databases including Apache Cassandra, LevelDB, and RocksDB just to name a few.
On a high level, LSM appends all incoming data then uses merge sort to handle deduplication and deletions. Underlying LSM are a few in-memory and on-disk data structures which will be explained in the following sections.
Sorted String Table (SSTable)
SSTable is a disk-based data structure consisting of a sorted, immutable sequence of key-value pairs. The sortedness allows for efficient data retrieval using algorithms like binary search.
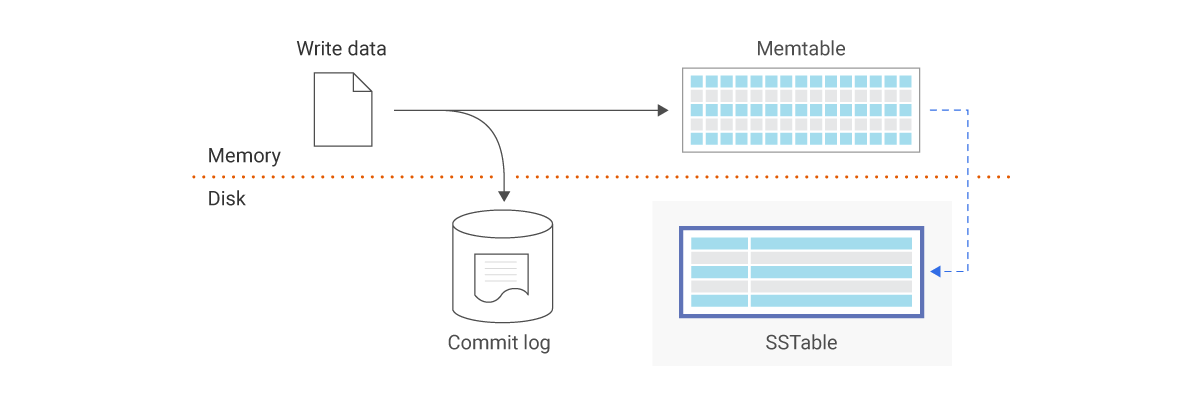
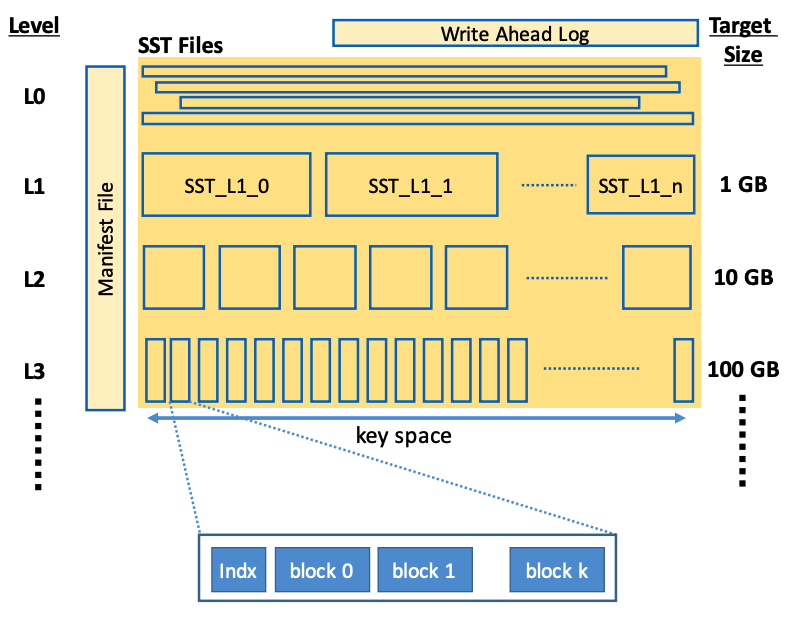
Initially, fresh write logs are buffered to an in-memory data structure called a Memtable. Once the Memtable reaches a configurable threshold, data is sorted and flushed to disk to become a new SSTable. In the diagram above, transactions are also appended to a Commit log or Write Ahead Log (WAL) file to recover from a crash and ensure durability. As more SSTables are added and a certain threshold is reached, the SSTables are merged via compaction to form a larger SSTable. Note that updates to a given key will just append the new key value. Older entries will eventually be removed during compaction.
Compaction
Compaction can be thought of as garbage collection for the LSM tree. It removes keys that are duplicated and/or marked for deletion. Under the hood, it utilizes a multiway merge algorithm to merge multiple SSTables into a new SSTable.
In most implementations, a dedicated background thread is used to perform compaction. There are many ways to customize how and when compaction gets triggered with different tradeoffs. Below are two classic compaction strategies.
Leveled Compaction

- Each level is a sorted run consisting of multiple SSTables
- When the run of level is full, it will flush and merge with the run of level
- Good read performance and lower space amplification since no duplicate keys are present in each level
Sized-Tiered Compaction
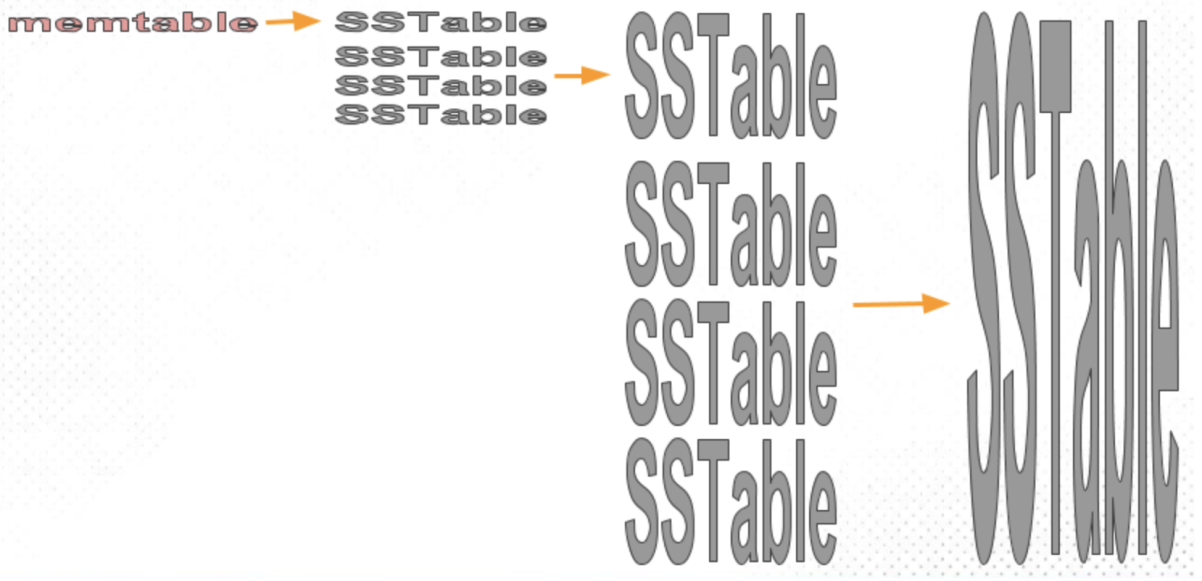
- Organizes SSTables into sorted runs based on their size
- Every level must accumulate runs before they are sort-merged
- When the number of runs , the whole level is merged to become a larger SSTable and flushed to the next tier
- Good ingestion performance since runs are lazily merged
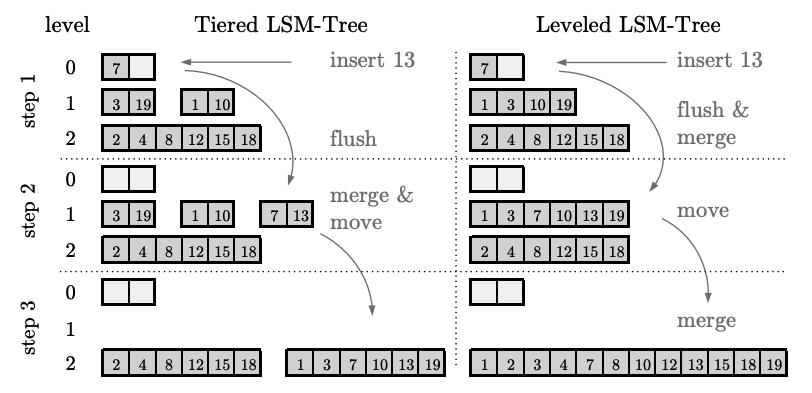
Tiered vs Leveled Compaction
Partial Compaction
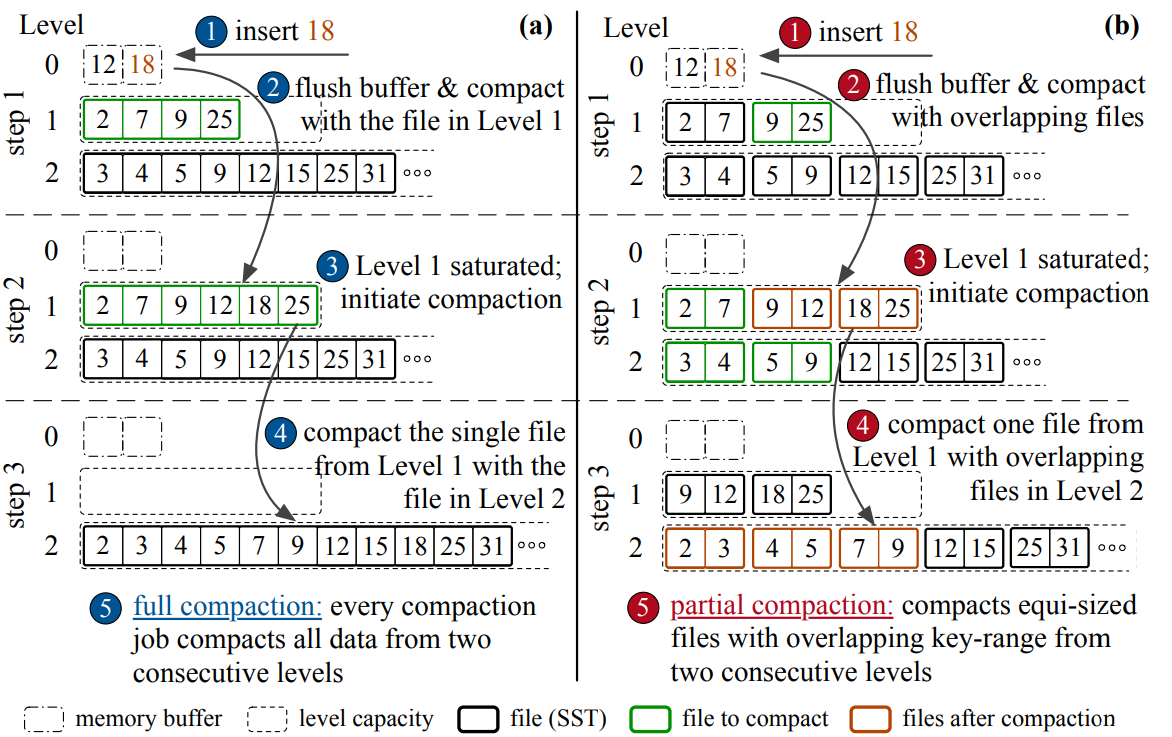
Leveled compaction can lead to cascading compactions, which results in high latency spikes, write stalls, and overall unpredictable system performance. Partial compaction aims to mitigate this by executing compaction with file-level granularity. The compaction condition/trigger remains unchanged. However, the compaction routine selects a subset of files from the current and next level with overlapping key ranges to merge. By breaking down compaction into smaller units, the cost is amortized, leading to more predictable and consistent system performance.
Data Movement Policy
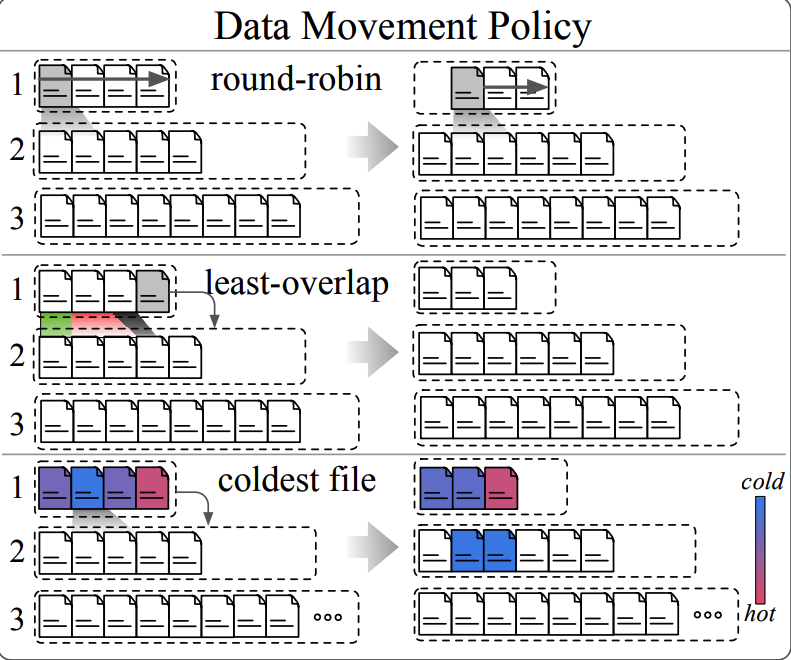
When executing partial compaction, we need to decide which data files to compact. Here are several policies (non-exhaustive), each with its own strengths:
- Round robin (default)
- Minimum overlap with parent level (improve write amplication)
- Coldest File (improve point query performance)
- File with most tombstones (improve space amplification)
Compaction Triggers
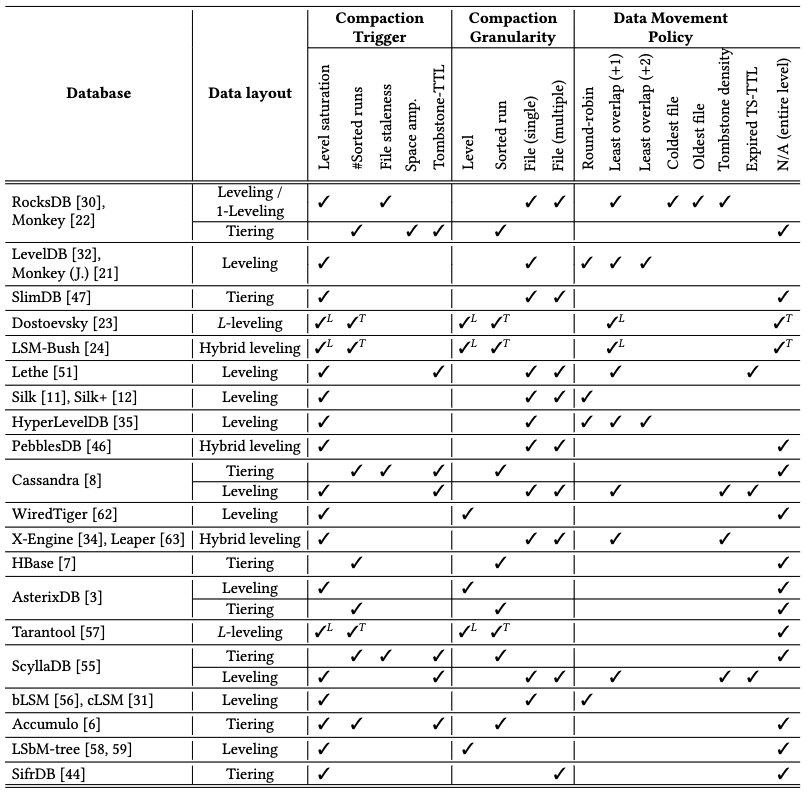
The two main compaction strategies discussed so far are leveled compaction, which is triggered when a level is saturated, and tiered compaction, which is triggered when the number of sorted runs exceeds a threshold . However, modern storage engines support additional compaction triggers. For instance, RocksDB’s Universal Compaction stores an estimate of each level’s space amplification and uses it to initiate compaction. Alternatively, compaction could be invoked based on the age of a file, i.e., how long it has existed in a particular level. This novel age-based compaction approach is an active area of research (more details in the last section). The table below summarizes the compaction algorithms employed by various research and industry storage engines.
Reading data
All reads in an LSM Tree are first served from the Memtable. If the key is not found, it is then looked up in SSTables by level until the key is found. Otherwise, a null value is returned.
Since duplicate keys may exist in the tree before compaction occurs, reads may require extraneous I/Os. Below are two main strategies to optimize read performance.
Bloom Filter
A Bloom filter is a probabilistic data structure that provides an efficient way to verify that an entry is certainly not in a set. A detailed explanation of how bloom filters work under the hood can be found here. Essentially, bloom filters sit between RAM and disk to reduce the amount of (expensive) disk reads. The SSTable will only be scanned if the bloom filter indicates that the key is likely to be present. Note that bloom filters by design only work for point queries, i.e., getting the value of a specific key, and cannot determine the presence of a key range.
Sparse Index / Fence Pointers
As the size of deeper levels increases, even using binary search to find a key can become expensive. To put this into perspective, RocksDB reports that on average, nearly 90% of storage data resides in the last level (Dong et. al, 2017). To mitigate the potentially large read cost, a subset of keys in each SSTable is mapped in-memory. With this key mapping, ranges can be quickly skipped, narrowing the search space and significantly reducing lookup time.
The sparse index, containing the key mapping, is typically encoded at the end of the file or as a separate index file. When an SSTable is read, its sparse index is loaded into memory and subsequently used for key lookups during read operations. Whenever compaction occurs, the sparse indexes are also updated.
Block Cache
The block cache stores metadata, including bloom filters and fence pointers, for the most relevant keys. These metadata structures are organized into pages within each sorted run on disk. When the block cache is initially empty, it fetches the necessary metadata pages from the on-disk files. It may also prefetch data pages to improve read performance. During read operations, the block cache is consulted first; if the requested key’s metadata or data is not found in the cache, disk I/O is performed. During compaction, all cached pages from the previous sorted run are invalidated to maintain consistency. Production systems like RocksDB implement a block cache, referred to as a Manifest File, as shown below.
Deletion
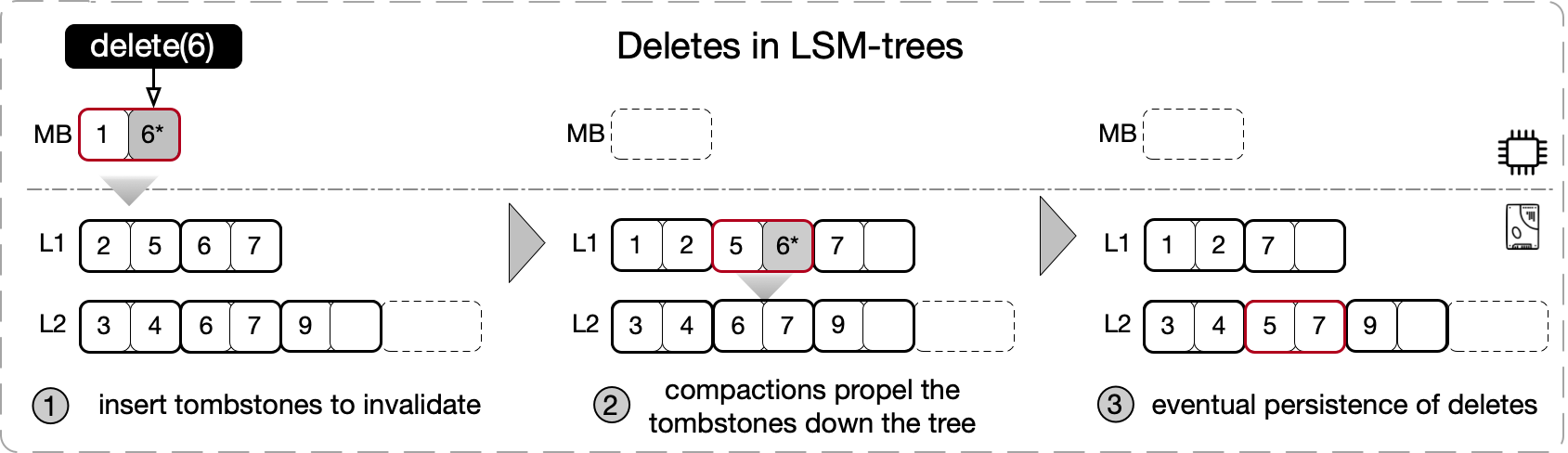
Deletes in LSM-trees are realized by inserting a special type of key-value entry, known as a tombstone. Once inserted, a tombstone logically invalidates all entries in a tree that have a matching key, without necessarily disturbing the physical target data entries. The target entries are persistently deleted from the data store only after the corresponding tombstone reaches the last level of the tree through compactions.
Research @ DiSC Lab
At Boston University’s Data-intensive Systems and Computing (DiSC) Lab, research is conducted on all aspects of log-structured systems to optimize performance. The main performance metrics and tradeoffs are listed below.
Read Amplification
Read amplification refers to the number of disk reads per query. As discussed earlier, read optimizations such as bloom filters and fence pointers significantly reduce read amplification by selectively processing read requests or reducing the search space.
Write Amplification
Write amplification refers to the ratio of the amount of physical data written to the storage device to the amount of logical data written to the database. Different compaction strategies result in different write amplification. In general, write amplification increases as the frequency of compactions increases.
Space Amplification
Space amplification refers to the ratio of the amount of physical data stored on the storage device to the amount of logical data in the database. Similar to write amplification, the compaction strategy employed significantly impacts space amplification. Size-tiered compaction generally results in higher space amplification compared to leveled compaction. In size-tiered compaction, when an SSTable in the deepest tier becomes very large, compaction requires substantial temporary space as the new, larger SSTable is written before duplicates are purged. Moreover, overwritten or deleted keys persist in the SSTable until it is eventually merged, leading to wasted space.
Tradeoffs
There are often trade-offs between different amplification metrics. For instance, introducing additional metadata to optimize write or read amplification can lead to increased space amplification. Compression techniques, employed by most storage solutions, help mitigate space amplification. Ultimately, the acceptable trade-offs depend on the system’s use case. Write-heavy workloads might prioritize minimizing write amplification and space amplification at the expense of higher read amplification. Conversely, read-intensive workloads may favor optimizing read amplification over the other metrics.
What I’m working on
At the DiSC Lab, I’m working on extending MySQL to incorporate application support for a novel LSM delete engine called Lethe. Lethe provides persistence guarantees for primary delete operations. A write-up of the motivations of the project and current progress can be found here. I will also provide a concise summary below.
We previously discussed that deletions in LSM are “lazily” materialized, meaning the “deleted” key is logically removed from the system only during compactions. Furthermore, a tombstone might need to be propagated through the last level of the LSM tree for the associated key to be physically removed, thus necessitating a full compaction. As the size of the tree grows, compaction might be delayed, and the process itself could be time-consuming. This introduces a significant challenge, as the duration between a deletion request from the client and the actual physical key deletion could extend to days or even months. Such a delay poses a considerable privacy risk for companies, particularly those committed to specific turnaround times for personal data removal (e.g., 30 days). In cases where company data is compromised, the persistence of user data beyond the stipulated period could result in legal complications for these organizations.
The envisioned long-term outcome of this project is to advocate for integrating the new SQL syntax into ANSI standards, establishing persistent deletes as a foundational capability in SQL. This paradigm shift aims to compel Database Management Systems (DBMS) vendors to natively implement persistent delete functionality. We hope to empower not only database engineers but also SQL users with greater control over their data lifecycles. This increased agency will enable them to meet Service Level Agreements (SLAs) and address various business requirements more effectively, particularly those related to data privacy and protection.
We are living in an era where emphasis on data security and privacy is paramount. Stringent regulations such as the GDPR and CCPA exist to minimize our data exposure by delineating strict guidelines for managing user data. Modern data systems must align with these legal frameworks, which are designed to safeguard our online privacy rights. I look forward to the successful realization of this project in light of these considerations.
References
What is a SSTable? Definition & FAQs | ScyllaDB
An In-depth Discussion on the LSM Compaction Mechanism
Lethe: Enabling Efficient Deletes in LSMs
SIGMOD 2022: Dissecting, Designing, and Optimizing LSM-based Data Stores (Tutorial)